
Hacked websites are known to result in a plethora of headaches for webmasters, including malicious redirects, broken links, and unwanted spam content. But did you also know that it can also result in problems for web crawlers like Googlebot and Bingbot?
Today we are going to look at how website spam can result in 404 errors in Search Console and what to do when it happens. If you use Google Search Console (and you should) we offer specific instructions to make sure you aren’t affected if you find yourself in a similar situation.
Contents:
- Common signs of SEO spam
- How does SEO spam get on my site?
- How to find spam doorway pages
- How spam can hurt SEO and lead to 404 errors
- Why does Search Console show 404 pages after removing spam?
- How to fix and remove 404 errors in Search Console after a hack
- 404’s for spam pages after forcing HTTPS
What are the most common signs of SEO spam?
Let’s start by analyzing the signs of a SEO spam infection, which can lead to issues with Googlebot and 404 errors in search console.
1 – Lots of new webpages appear on your site
SEO spam infections like the Japanese keyword spam are known to create tens of thousands of spam files on a website. These are usually JavaScript and HTML files.

2 – Website page titles and descriptions have changed
One common indicator of SEO spam includes changes to your Google search results pages. You’ll likely find them riddled with spam keywords and content.
3 – Write failed: disk quota exceeded warnings
Since some SEO spam campaigns can create a huge number of files, you might find that your hosting account has used the maximum amount of disk space allowed by your quota.
Once you’ve addressed these issues and cleaned up the spam, however, you might end up with a whole different set of problems.
Next, let take a peek at some of the common ways SEO spam gets on your site in the first place.
How does SEO spam get on my site?
The initial method of infection can vary from site to site.
In some cases, an attacker may brute force their way through an insecure admin page or reuse stolen passwords from a data breach. Or they might leverage known vulnerabilities in popular plugins, themes, and extensible components to gain unauthorized access to your site’s environment.
Regardless of how they manage to obtain a foothold, once they’re in they’ll exploit your system’s resources and website rankings for their own purposes.
As an example, let’s discuss one of the common methods used to create and rank for spam on a website.
- Attacker gains unauthorized access to a website.
- Once a foothold has been established, the hacker creates spam doorway pages on the infected website. These include spam keywords that help them rank in Google search results for relevant queries.
- When a user clicks on this search result, the doorway redirects the visitor to the hacker’s third-party website — and they never really end up on the infected pages at all.
Here’s where it gets interesting. Google ranks the doorway pages if there are many incoming links to those pages. This is one of the main ways that Google’s algorithm identifies “good” search results.
Attackers know that nobody will be linking to their secret doorway pages. So they link back to the spam doorways on other hacked websites, creating a complex interlinking strategy in the process.
How to find spam doorway pages
Here’s an example using Unmask Parasites to uncover one of those doorways and its external links from hacked sites.
Simply pop a URL into the tool and it will provide a list of external references, as seen below for this site that’s been infected with Japanese SEO spam.
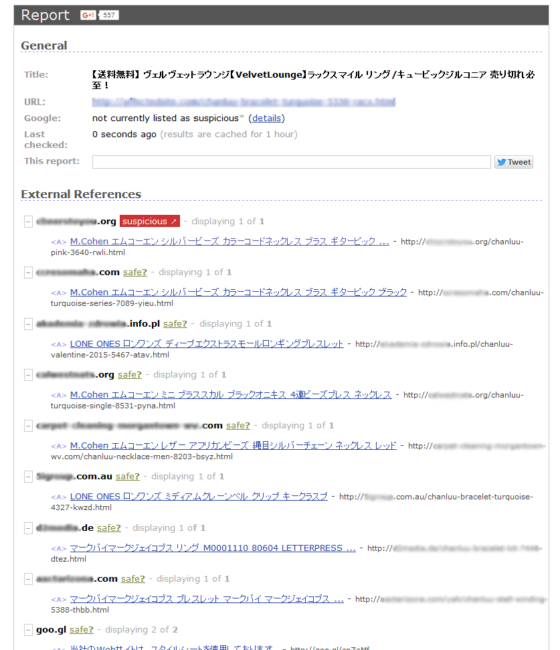
Now, let’s do the math.
- A typical spam campaign infects around 3,000 sites.
- Each site has at least 25,000 spam pages/doorways (usually more).
- Each doorway has at least 5 links to other hacked sites.
- This gives us around 125,000 outgoing links per hacked site.
- Since they are evenly distributed between all the compromised sites, it means that each hacked site has about 40 links to every other hacked site.
This means that all the hacked sites, combined, have around 125,000 thousands links to doorways on each individual hacked site. Even this is probably an underestimation since they usually create more than one directory with spam files, each of which contains 20,000+ spam files.
As you see, there are an enormous amount of incoming links to your site — and Google can see them too.
How spam hurts SEO and leads to 404 errors in Search Console
Let’s take a look at how this problem of incoming spam links affects your SEO and what happens once you clean them up.
As we previously calculated, if you’re compromised with SEO spam there could be over 125,000 references on the web pointing to the spam on your website. This means that Googlebot will eventually crawl them on the other infected sites and start crawling your website for those links.
If the spam is not cleaned up promptly, it can cause a sharp drop in your SEO rankings as it generates a huge amount of spam doorways that drain your link juice and lower your reputation. You’ll also be penalized and even possible blocklisted by search authorities if your site is found to contain malicious content or redirects to malicious websites.
And once you do clean up all those spam files, Google will still eventually try to crawl them because the backlinks were most likely posted somewhere else already. This can create a tremendous amount of 404 errors on your Google Search Console (Webmaster Tools) panel.
Note: In general, the 404 errors found in Google Search Console after a hack won’t impact your site’s search performance but they can be a nuisance for your reports. These errors will likely disappear from your Search Console reports with time, but it can take weeks or even months to resolve — and will clutter up existing reports, making it harder to detect or pinpoint legitimate issues.
Why does Search Console show 404 pages after removing SEO spam?
Let’s take a deeper look at why Google might show more 404 pages after you remove the spam from your website.
When attackers initially infect your website with SEO spam, they create numerous pages — but Googlebot doesn’t always find references to them yet. And even if it does, the pages exist so they don’t return a 404 error.
Furthermore, Google usually doesn’t crawl the thousands of spam pages all at once, even though there have been reports of Google crawling too many pages at the same time and crashing websites. To prevent performance issues, Googlebot usually has a quota on the number of pages they can crawl on any particular website in a day — especially when a website is not known to produce tons of content on a regular basis. (You can find the average number of crawl requests for your site in the Crawl Stats report in Search Console.)
The same thing has happened on the other hacked sites sending links to your spam pages. Over time, Google gradually increases the number of crawled spam pages it can handle daily (and new links to your site).
Remember those attacker-controlled spam doorways interlinking to the spam pages on all those hacked sites? Well, even if the infection on your website has been cleaned up and the cache has been cleared, there may be thousands of links to the spam pages you removed still queued for Googlebot to crawl. Additionally, Google will try to crawl the spam links it had already previously crawled to update its own index with the best results possible. And all of these can throw a 404 error in your Search Console.
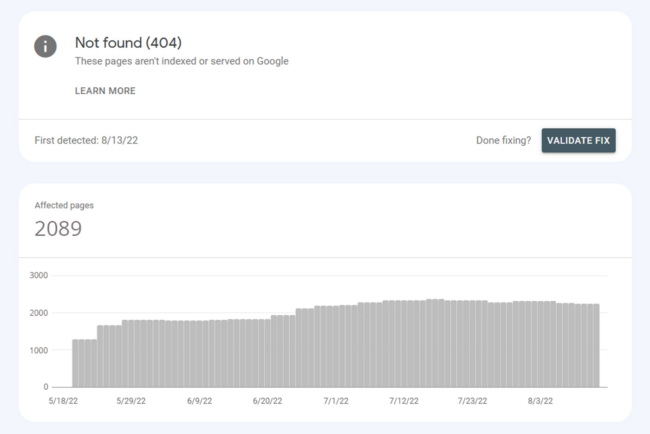
So, if your site has been cleaned up and is no longer infected, you may still experience the long term side effect of the hack as Google’s attempts to re-crawl thousands of non-existent spam pages for a few more weeks or months.
If left alone, Google will re-crawl the already indexed doorways on your site and eventually notice they’re all gone. Google will try to crawl deleted pages a few times to ensure they’re gone for good before removing them from their index. This ensures that the 404 is not related to some temporary maintenance issue.
How to remove 404 errors in Search Console
The first step is to clean up the SEO spam from your website. Once that’s done, you’ll need to tackle the huge number of 404 pages that Googlebot expects to find.
We’ve outlined three possible options for you to tackle and remove 404 errors from Search Console.
Option 1: DIY with Search Console’s URL removal tool
If you want to get your hands dirty, you can use the URL Removal tool in Search Console.
It’s a great method for a small amount of links and it should show results quickly (within 24 hours), however, it’s difficult to submit all the links one by one.
Also worth noting that it doesn’t remove URLs from Google’s index. Instead, it temporarily removes URLs from showing in search results — so you’ll want to make sure that you’ve cleaned up all portions of the infection before you take this approach.
Option 2: Return a 410 HTTP response instead of a 404
Returning a 410 (Gone) HTTP status response from the server tells Google that you have specifically and intentionally removed the page from your website and it no longer exists.
Unlike a 404 error, which states that the page cannot be located, a 410 response will help clarify that the page is gone. This can help speed up the process of removing 404 errors from Search Console.
To set this up on an Apache server, add the following line to your .htaccess file using the mod_alias Redirect directive.
Redirect gone /path/to/resource
Once you’ve added this for the offending 404 URLs, you’ll effectively tell Google that the spam pages have been permanently removed and aren’t expected to return.
Option 3: Wait patiently
Another tried and true method is to simply wait it out.
The length of time it takes for Google to re-crawl your website depends largely on two factors:
- The number of pages your site has.
- How intensively Google is crawling your website on a daily basis.
Average crawl times can range from a few days to weeks. But, the majority of the time, Google (and other search authorities) eventually understand that the pages are in fact gone and no longer exist. At this point, they’ll stop reporting them as 404 errors.
Tackling 404’s for spam pages after forcing HTTPS
In some cases, we see webmasters force https:// redirects immediately after cleaning up a hacked website, which can also cause some issues with spam URLs showing up as 404’s in Search Console.
SSL provides numerous security benefits as well as improvements to Google rankings and performance through the use of HTTP/2. Most notably, it protects data in transit. This is crucial for transferring sensitive credit card information on checkout pages or handling details on login and contact forms.
However, by forcing the redirect immediately after cleanup, Google isn’t able to crawl these http:// version of the URLs. That means it can’t verify that they’re gone, and the spam will stay in Search Console indefinitely. This is typically resolved when the SSL redirect is either removed for a few weeks or the webmaster returns 410 HTTP responses for the spam URLs.
In this scenario, the best solution is to get your sitemap properly rebuilt for the HTTPS version of your site — but don’t enforce the redirect for Googlebot right away. You can still force the redirect to HTTPS for actual website visitors but make sure you allow Googlebot to crawl the website at will.
Properly allow Google to crawl your HTTPS website and verify that the spam pages are no longer present. This will help prevent 404’s from appearing in Google Search Console.








