
We are no strangers to Blackhat SEO techniques, we’ve actually spent a great deal of time working and sharing various bits of information related to Blackhat SEO techniques over the years. What we haven’t shared, however, is the idea of Proxy-based Spam Networks (PSN). It’s not because it wasn’t interesting, it’s just not something we’d seen that often, or at all. As is often the case in the website security, techniques continue to evolve, they’re mastered and as such the space changes and it’s on us to understand, dissect and of course, deliver that information to each of you.
This naturally brings me to the latest trend we’re seeing, while difficult to quantify (you’ll soon see why) we have started to see and experience interesting configurations in which Blackhat SEO actors are employing the use of reverse proxies to:
- Hijack and rank for your content.
- Leverage that ranking for their own SEO needs (often with nefarious intentions).
Blackhat SEO
For those unfamiliar with Blackhat SEO, let’s take a minute to define it. In perhaps an overly simplified explanation, I categorize Blackhat SEO as a means of abusing SEO ranking in search engine results pages (SERPs) with little regard to the audience, as much as the SERP itself. Their tactics are often frowned upon, and / or bend the rules set forth by search engines, regardless of the platform (i.e., Yahoo, Google, Bing, etc..).
I was very specific not to imply who the owner of the website was, as most can often use their own website in shady, or otherwise categorized as Blackhat SEO practice. At the same time, it’s often reserved for those wishing ill intent on a website they don’t own through means of hacking (be sure to learn how website get hacked).
Reverse Proxies
I think it’s important to talk a little about reverse proxies as well, and the role they play in the larger web these days.
Reverse proxies are becoming more and more prominent as a part of the fabric of the internet. As implied by the name, it sits in the middle of a communication between client and web server, directing the information appropriately to the servers housing the information being requested. The system requesting the data is none the wiser regarding the origins of the data, it just knows something is responding to its request. It is an ingenious approach to handling large volumes of data and it’s a configuration technique employed by a variety of technologies like cloud-based Website Application Firewalls (WAF) and Content Distribution Networks (CDN) – similar to our own technology.
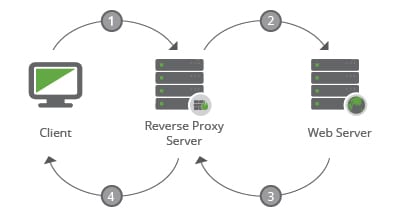
Reverse Proxies Leveraged in Blackhat SEO Campaigns
With this basic understanding, let’s dive into some of the interesting things we’re seeing regarding Reverse Proxies and Blackhat SEO campaigns, or what we’re coining Proxy-based Spam Networks (PSN).
This example, comes from one of our customers, which will go unnamed:
Hello Sucuri Team,
We just found a site that is copying EVERYTHING on customer.com and replacing the logo with notcustomer.com If you go to notcustomer.com, you’ll see that the content, theme, and everything else is a mirror image of our site (i.e., customer.com).
Is this a hack? We don’t know what this company is or how it was able to copy all of this and the site notcustomer.com is not one of customers. What do we do?
Thanks!
Technically, it wasn’t a hack; the attacker had not penetrated the customers environment. They did however employ some very sneaky techniques. The attacker configured a reverse proxy to customer.com unbeknownst to the website owner. It’s actually not that difficult or surprising it went unnoticed. To the customer.com web server it was just perceived as legitimate traffic, and in fact it was, but with ill intentions of course.
Analyzing The Campaign Configuration
The following analysis was provided by one of the managers running our Security Operations Group (SOG) – Bruno Zanelato.
According to my research, I figured out that the domain “notcustomer.com” is working like a reverse proxy to website “customer.com”, let me explain:
I created a test.txt file for testing purposes with the word “sucuri” in the body of the file; I could then use this to upload the file to the server to see what might be happening. Using terminal, I was able to then test if I was able to access the file from both domains:
wget http://www.customer.com/test.txt –2015-09-09 11:48:27– http://www.customer.com/test.txt Resolving http://www.customer.com/test.txt (www.customer.com)… 75.307.150.50 Connecting to http://www.customer.com/test.txt (www.customer.com)|75.307.150.50|:80… connected. HTTP request sent, awaiting response… 200 OK Saving to: ‘test.txt.’
$ cat test.txt sucuri
So that’s pretty cool, it worked – but that’s expected. What happens when I try it on the cloned site?
wget http://www.notcustomer.com/test.txt –2015-09-09 11:48:27– http://www.notcustomer.com/test.txt Resolving http://www.notcustomer.com/test.txt (www.notcustomer.com)…162.159.210.11, 162.159.211.11 Connecting to http://www.notcustomer.com/test.txt (www.notcustomer.com)|162.159.210.11|:80… connected. HTTP request sent, awaiting response… 200 OK Saving to: ‘test.txt.’
$ cat test.txt sucuri
What the heck? How is that possible? We created the file.txt file only on customer.com, how is it that I’m now downloading it from the notcustomer.com domain too?
You likely see where I’m going with this, and yes in hindsight it appears to be such an obvious explanation, but I’ll be honest it didn’t feel so obvious at the time. The answer was simple, the notcustomer.com domain was simply functioning as a reverse proxy to customer.com. This allowed the user to steal all the content and information, as well as SEO juice, from the good site, while adjusting the outputs of the site to a different audience, without ever having to actually hack into the target website.
Well, that’s just plain rude!
How the Configuration Works
When we request the test.txt file from the original website:
USER -> http://www.customer.com/test.txt -> resolves to 75.307.150.50
When we request the test.txt file from the fake website:
USER -> http://www.notcustomer.com/test.txt ->resolves to 162.159.211.11 and then request to original website -> 75.307.150.50
The attackers were able to employ the basic techniques employed in reverse proxies to effectively abuse a website, without the website owner even knowing they had a problem. The intentions are the same as any Blackhat SEO campaign, leverage someone else’s ranking / SEO to abuse audiences and push their agenda – whether political, malware related or some other nefarious action.
Stopping Blackhat SEO Campaigns Leveraging Reverse Proxies
Fortunately, stopping the attack is pretty straight forward – at least in theory.
Once you know the originating IP for the reverse proxy, you can simply block it from accessing your web server. In this case, once we knew what IP’s to look for we were able to engage our NGINX logs to understand the originating IP of the reverse proxy server:
root@server:/var/log/nginx# tail -f customer.com.access.log | grep test.txt 104.250.139.18 – – [09/Sep/2015:07:59:31 -0700] “GET /test.txt HTTP/1.1” 200 7 “http://www.customer.com” “Wget/1.15 (linux-gnu)” “104.250.139.18”
this – > 104.250.139.18
$ host 104.250.139.18 18.139.250.104.in-addr.arpa domain name pointer 104-250-139-18.static.gorillaservers.com.
With this information, we’re armed with everything we need to do to block access from this IP. This however presents an entirely different problem most have likely not accounted for, how to handle these reverse proxy SEO attacks? What else can be done in these configurations? Have you experienced something like this before?








11 comments
Do these mirror sites inject any additional content, such as JavaScript, ads or exploit kits?
At the moment, we’re not seeing anything on the malicious site outside of SPAM, but there would be nothing stopping them if they wanted to.. as for the main, benign site, no…
I have seen these sites strip out my original analytics and adsense scripts from my pages. They are also serving their own additional scripts on their reverse proxy. They also are caching my pages.
Is there an easy way to detect that though ? I had a reverse proxy on my blog about a year ago. I figure it out just out of luck because one of the URL for an image hadn’t been change to the URL of the mirror, so my hotlinking detection script found that out. But otherwise, it’s a bit tricky to detect it, isn’t it ?
They can also use it to negatively affect your ranking, can’t they? Copying your site to multiple domains would mean duplicate content.
How to know whether my website is under a reverse proxy attack?
I’ve been attacked by same network…the offender seems to have 1000s of sites and IPs.
Is there a way to *automatically* detect a reverse proxy?
How can we know that attack is detected to site ?
Thanks .
🙁
..
My solution would be to couple a reverse-proxy onto theirs. Requests from the offender’s IP addresses would be sent a fake Godaddy “this domain may be for sale”. Or you can be more creative 😉
Suggested to me by a colleague: “A better way to deal with reverse proxy sites… add a validation file in WMT and add yourself as an owner, then delist them”
Comments are closed.